4.4. k-nächste-Nachbarn-Algorithmus
Dies ist ein relativ einfacher KI-Algorithmus für Klassifikationsaufgaben (k ist dabei die Anzahl der zu berücksichtigenden Nachbarn):

Bei einem konkreten Beispiel soll es um 2 mögliche Kategorien bzw. Klassen und 9 bekannte Datensätze gehen (siehe Abbildung 36).
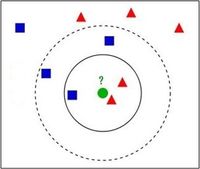
Abbildung 36 (*Q32): Nächste Nachbarn in Abhängigkeit von k (hier 3 und 5)
Bei einem neuen Datenwert (grüner Punkt) soll der Algorithmus entscheiden, ob dieser Wert der Kategorie „rotes Dreieck“ oder „blaues Quadrat“ angehört. Je nach dem gewählten Wert von k gibt es unterschiedliche Ergebnisse:

Wenn der neue Datenwert aber ein Testdatenwert ist, bei dem die Kategorie bekannt ist, dann kann man auf diese Weise den am besten geeigneten k-Wert ermitteln. Sollte das gewünschte Ergebnis „blaues Quadrat“ lauten, dann wird der Algorithmus mit k = 5 initialisiert.
Hinweis: In der „KI-Realität“ hat man natürlich nicht nur einen Testdatenwert, sondern sehr viele Testdaten. Dann wird geguckt, für welches k die Summe der Fehler am niedrigsten ist.

- 37 -
