4. Lernen mit einem Neuronalen Netzwerk und mit Java
Neuronale Netze (NN) sind das relevanteste Gebiet des Maschinellen Lernens (*Q23). Sie bestehen in der Regel aus einem Input-Layer, an den die Eingangssignale (Daten) angelegt werden, einer Anzahl von sog. Hidden-Layern (jeder mit einer bestimmten Anzahl von Neuronen) und einem Output-Layer, der das Ergebnis liefert.
Sie sind z. B. in der Lage aus Bildern, Videos oder Tönen gewisse Zusammenhänge zu finden bzw. Muster zu erkennen. Auch können sie Daten strukturieren bzw. kategorisieren.
Es gibt noch viel mehr Arten von Neuronalen Netzen als das eben beschriebene Feed-Forward-Netzwerk. Z. B. gibt es das Convolutional Neural Network (CNN) zur optimalen Bilderkennung, das Genetic Neural Network (GNN), welches sich die Evolution zum Vorbild nimmt und das Recurrent Neural Network (RNN), welches mit Rückkopplungen arbeitet und somit quasi ein Gedächtnis hat.
Eine sehr gelungene Visualisierung für das Lernen mit einem Feed-Forward-Netzwerk stellt das TensorFlow-Framework unter “http://playground.tensorflow.org/“ zur Verfügung. Hier kann man mit verschiedenen Hyperparametern „herumspielen“ und dann dem Netzwerk beim Lernen zugucken.
Die erste Konfiguration (s. Abbildung 23) hat zwei Eingänge und einen Hidden-Layer mit vier Neuronen. Es geht um eine Kategorisierung von Bildpunkten in blaue und beige Punkte. Nach 776 Episoden liegt der Fehler (loss function) sowohl bei den Trainings- als auch bei den Testdaten (mehr dazu in Kapitel 4.2) bei 0.01.
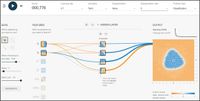
Abbildung 23 (*Q24): Simulation eines Feed-Forward-Netzwerkes mit einem Hidden-Layer und der Aktivierungsfunktion Tanh

- 25 -
